2020.07.28


Treasure Workflowとは?
Treasure Dataはマーケティング施策で使用される多種多様なデータを収集、分析、活用できるデータプラットフォームです。今回はTreasure Dataの中でも、データ処理を自動化・管理することができるTreasure Workflowという機能について解説します(図1)。
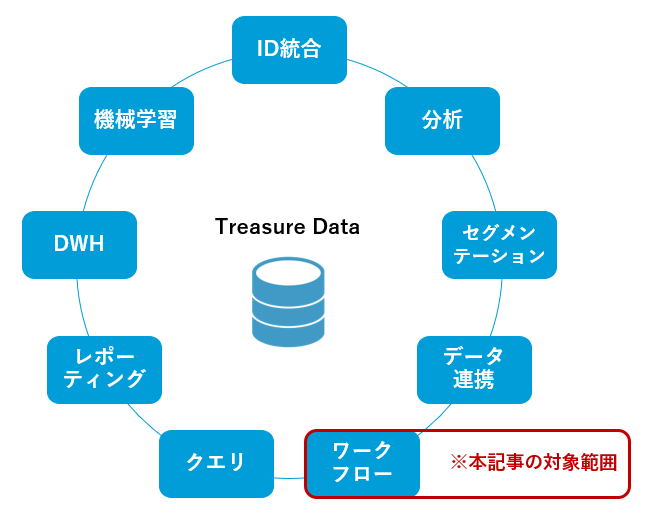
(図1:Treasure Dataの機能)
Treasure WorkflowとはTreasure Dataの機能の1つで、データ処理のためのワークフローマネジメントサービスです。Treasure Data上での各種処理をワークフローとして自動化・管理することができ、複数のクラウドやWebサービス上にあるデータをシームレスに統合させて運用することができます。具体的な機能としては、以下の3点が挙げられます。
1.クラウド・ストレージやサーバからデータをインポート後、SQLによるデータ処理指示の実行、結果の書き出しといった処理の一連の依存関係を考慮した形で管理できる。
2.データ処理の際にエラーが発生した場合のメール通知機能もあり、再実行も簡単にできるため迅速に復旧できる。
3.スケジュール登録機能も備えているため、定期的にデータ処理の実行を簡単に設定できる。
これらにより、企業内のデータ処理を自動化することでリアルタイム性に優れ、素早くデータ分析ができるようになります。なかでも複数ベンダーのクラウド基盤上のデータをつなぐことで、企業内のさまざまなデータをシームレスに統合・運用するプロセスを構築できることは大きな利点です(図2)。具体的にはGoogleのBigQueryやG Suite、AmazonのAmazon Redshift、MicrosoftのAzureなどのクラウドサービス上にあるデータが相互にアクセスし合うことができるようになります。
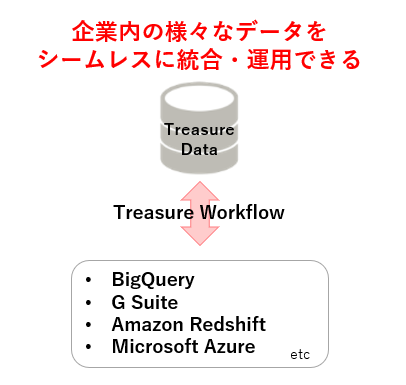
(図2:企業内データをシームレスに統合・運用)
利用方法イメージ
Treasure Workflowでは図3のようにサービス間連携できるData Connectorを選択し処理対象データを指定・取得後(図3:Task1)、SQLによるデータ処理の指示をおこない(図3:Task2)、処理結果をTreasure Data内や他のツールへエクスポートする(図3:Task3)一連の流れを登録することができます。
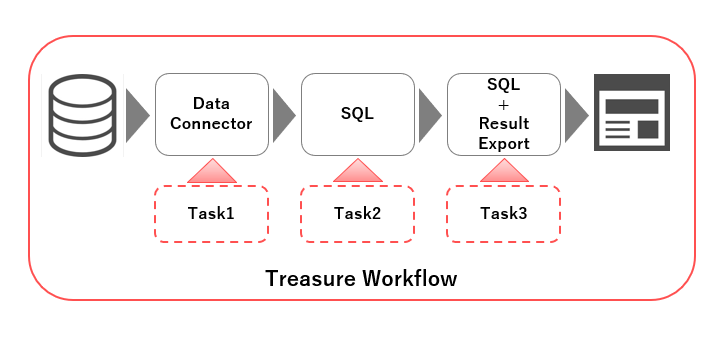
(図3:利用方法イメージ)
Treasure Workflow作成方法
次に実際にワークフローを作成する手順を解説します。
ワークフロー作成手順
ワークフローは以下の5つのステップで作成することができます(図4)。

(図4:ワークフロー作成のステップ)
1.プロジェクト&ワークフローの新規作成
Treasure Workflow はプロジェクト内にデータ処理を指定したワークフローを作成し、プロジェクトファイルにさらに詳細な処理内容を指定することで作成していきます(図5)。そのため、まずはプロジェクトから作成する必要があります。
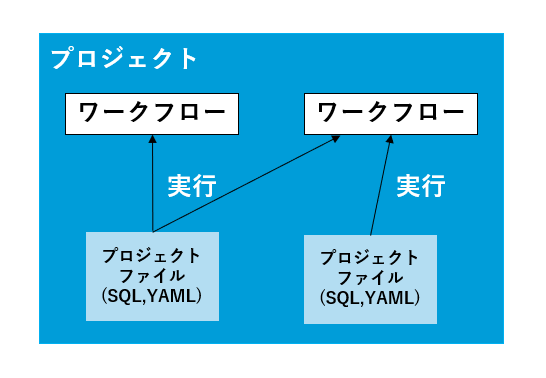
(図5:プロジェクトとワークフローの関係性)
2.DIGファイルによるワークフローの定義
プロジェクトを作成後、ワークフローを作成します。ワークフローはタスクとオペレータで構成される実行ファイル(DIGファイル)を編集することで、いつ、どこで、どのようなデータ処理をおこなうのかを具体的に定義します。
3.プロジェクトファイルの追加
ワークフローを作成する中で、どのようなデータ処理をおこなうのかを、さらに具体的にSQLなどで記述したプロジェクトファイルを追加します。
4.実行
1~3にて作成したワークフローを実行します。実行する際に、データ処理をおこなうセッション時間(日時)を指定することもできます。
5.実行の監視・実行履歴
ワークフローの実行後、それらの実行履歴を保持・再実行することができます。実行履歴では、登録したタスクの実行状況をタイムラインに沿って確認することができます。エラーが出た場合にはどのタスクで不備があったのかが可視化されるため、そのタスクを指定し出力ログを確認することができます。
このようにワークフローを作成後、データ処理が設定どおりおこなわれているかの確認を経て、データを統合・運用していくことができます。
ワークフロー記述法
次にワークフロー作成手順2にあたる実行ファイル(DIGファイル)の記述法についてさらに詳しく解説します。実行ファイルでは大きく分けて以下の3点(いつ、どこで、どのような処理をおこなうのか)の処理を指定する必要があります(図6)。
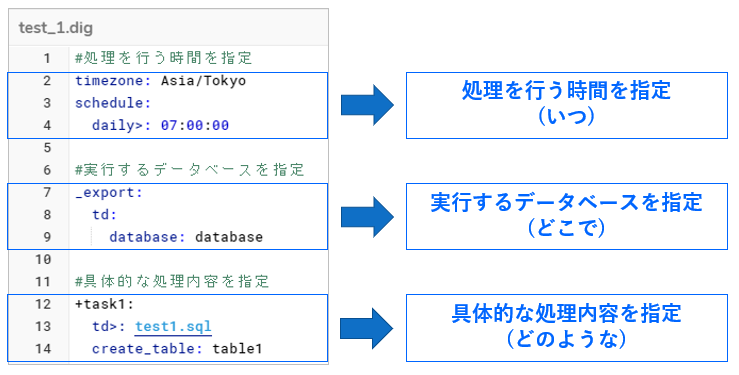
(図6:ワークフロー記述の手順)
上記を記述していくうえでのポイントは以下になります。
・実行ファイル(DIGファイル)をYAML形式で記述する。
・“+”によってタスクを定義する。複数のタスクも同時に実行できる。
・スケジュール設定できる。
・変数${…}やオペレータ(図7)を利用することで具体的な処理内容を指定できる。
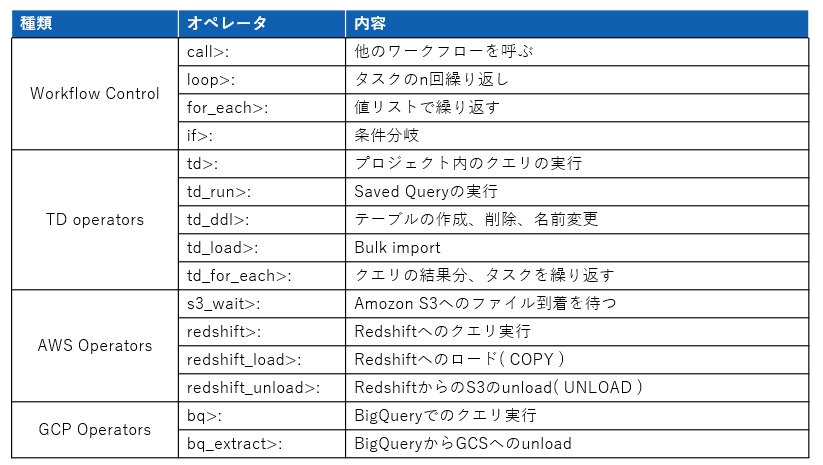
(図7:主なオペレータ例)
Treasure Workflowの活用メリット
1.社内の部署・職種間の隔たりを改善
企業は複数ベンダーのクラウド基盤を利用してデータ管理をおこなうことが多くあります。データ活用やワークフロー管理が複雑になると、社内での部署・職種間に隔たりができ、企業内データを統合した分析がしづらいという課題があります。そこでTreasure Workflowによって顧客データを管理し、従来関連付けることのできなかった異なるデータソース間をつなげ、ワークフローが統合されることでシステム開発者やデータサイエンティスト、データ運用者など、社内の部署・職種間の隔たりを改善することができます。
2.業務の効率化・意思決定の迅速化
Treasure Workflowによりデータ処理を自動化することで作業時間が短縮されます。例えば日々作成している集計レポートを毎回手動で出力していた場合、自動化されることで効率化・工数削減の実現につながります。したがってデータ処理に従事していた時間を本来するべき業務に当てることで、作業効率や労働生産性の向上に繋がるといえるでしょう。また、人が長時間作業をおこなうと集中力が低下し、ミスが増えてきますが、データ処理を自動化すれば 正確に業務を遂行することができます。スケジュール設定が可能なため、例えば売上の管理などデータが蓄積された時点でのデータ処理をすることができ、リアルタイム性に優れることから、迅速な意思決定にもつながります(図8)。
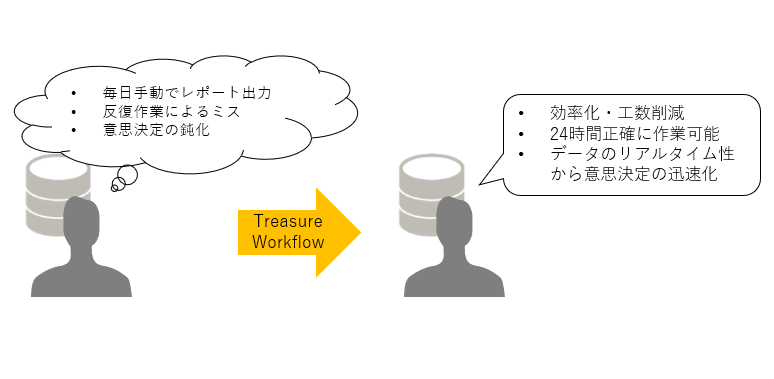
(図8:Treasure Workflowを用いて業務を効率化)
まとめ
本記事ではTreasure Dataをデータ基盤としたデジタルマーケティングを推進するために、そのうちの機能のひとつであるTreasure Workflowについて解説しました。データを有効活用すべきと考える企業が増えているなかで、部署間でのデータ連携がうまく取れていない、データ集計に工数がかかっている、といった課題を抱える企業は多いと考えます。Treasure Workflowを活用することで社内のデータをシームレスに統合・運用でき、さらに精度の高い分析や施策に繋げることが可能になります 。当社では、Treasure Dataの導入から活用までの支援を一貫してご提供しております。今回ご紹介したTreasure Dataを活用したデータ統合・活用に興味があればぜひアイレップへお問い合わせください。
